

An Introduction to Domain-Driven Design (2/3)
Joas Bjerre Haunstrup
Software Craftsman - Graduate 4. October 2024 Graduates
Graduates
In this second installment of my series on Domain-Driven Design, I will explore some of the central concepts of DDD.
Central concepts
When building your model you will find that the it is possible to express the domain in a lot of different ways, that are all equally valid from an analytical standpoint. However, not every model is equal when it comes to how simple it is to turn into code, which you have to do at some point. While it can be difficult to evaluate how difficult it is to turn a model into code before actually doing it, DDD comes with concepts that will help you build a model better suited for it.
In the following I will introduce you to a couple of the most central of these concepts.
Entities and Value Objects
In our model, we will have some objects, which can generally be categorized into two types: entities and value objects.
Entities are objects that have an identity. An example of this could be staff members. While the only information we need to show about a staff member might be their name, we also need some kind of unique identifier to keep track of each staff member, even if they might happen to have the same name. This unique identifier might be something external like a social security number, or we could make our own internal identifier by assigning a unique staff id to each staff member.
Contrary to entities, value objects are defined solely by their values. If two value objects have the same values, there is no distinction between them. They are typically short-lived, and should be immutable. If you need an object with different values, you should simply create a new one. An example in our system might be a time slot representing a specific time range during a day. If two time slot objects have the same start and end times, they are considered identical and we don’t need to distinquish between them.
Services
Services are operations that do not naturally fit within the entities or value objects. They are stateless and often encapsulate domain logic. For instance, what should be responsible for orchestrating the creation and modification of a weekly schedule? It doesn’t really fit into the schedule itself, and it would also seem misplaced in any of the other entities or value objects that we have. Hence, we can create a ScheduleService for this purpose.
Bounded Contexts
Bounded contexts are used to clearly define boundaries within a domain, ensuring that concepts, rules, and behaviors are consistent within each context. In our example, we could have a bounded context named Scheduling that includes all the entities, value objects, and services related to managing work schedules. Separately, we could have another bounded context called Inventory which keeps track of the products being sold, their prices, how much is left of each and other things related to the shop’s inventory. This could be illustrated in the following way:
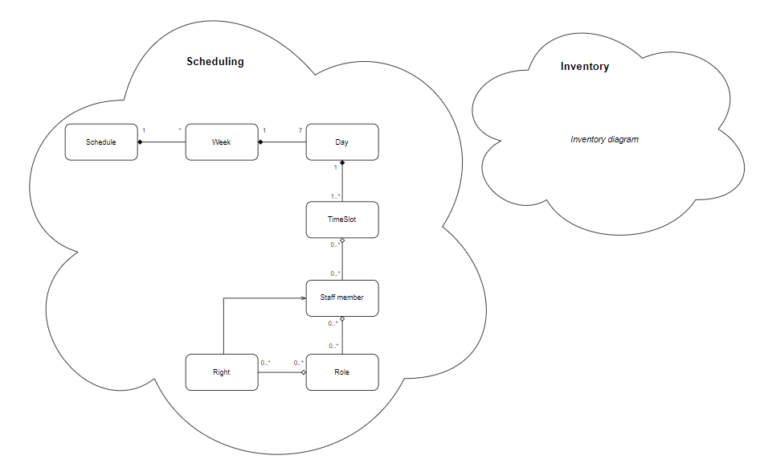
This separation of contexts helps to avoid confusion and makes it easier to modify one part of the system without affecting other unrelated parts, which makes the system more maintainable and flexible. Sometimes two bounded contexts need to integrate with each other. There are different patterns for managing this integration, depending on the nature of the two bounded contexts and the relationship between them. Generally, the integration should be handled in a well-defined, limited area within each context, ensuring that the rest of the bounded contexts remain decoupled and independent.
Aggregates
Aggregates are clusters of domain objects that can be treated as a single unit. Each aggregate has a root entity, called an aggregate root, which ensures the consistency of changes being made within the aggregate. In our example, Schedule could be an aggregate root that includes Week, Day, TimeSlot and StaffMember.
The aggregate root controls access to the aggregate‘s internal components. This means that other parts of the system should never interact with the contents of the aggregate directly. Instead, all interactions must go through the aggregate root. This design principle helps maintain the integrity and consistency of the aggregate by ensuring that all changes are controlled and validated by the aggregate root.
For example, if you need to add a StaffMember to a Day, you would do this through methods provided by the Schedule aggregate root rather than directly modifying the Day or StaffMember objects. This approach prevents accidental inconsistencies and ensures that all business rules and invariants are upheld.
Factories
Factories are useful when you need to create complex objects and aggregates. They encapsulate the logic needed to instantiate an object, ensuring that the creation process adheres to the business rules and constraints of the domain. This is particularly useful when an object’s creation process involves multiple steps or requires setting up various components.
In our flower shop system, a factory could be used to create a Schedule. Creating a Schedule might involve initializing weeks, days, and assigning initial staff members. By using a factory, we ensure that the Schedule is created consistently and correctly every time. Factories also help keep the creation logic out of the entities, which reduces their responsibility and improves testability and maintainability by having the creation logic in one place.
For example, if creating a Schedule involves validating dates, ensuring no overlap of time slots, and assigning staff members to time slots based on some template, a ScheduleFactory would handle all these steps, providing a clean and consistent way to instantiate Schedule aggregates.
Repositories
Repositories provide an abstraction for data access, focusing on retrieving and storing objects. In our example, we could have a ScheduleRepository for storing Schedule aggregates. Initially we might just store schedules in memory while we focus on the core logic of the application, but at some point we need to persist the schedules, for instance in a SQL database. As we have isolated the retriving and storing of schedules into a repository, we can leave the domain logic unchanged while only modifying the repository.
A repository will normally support CRUD (create, read, update, delete) operations, but it can also make sense to support some more specific operations, that are relevant for the given domain. This will allow for optimisations in the repository, that would not be possible in the code that uses it, as only the repository knows about how the objects are stored. The more domain specific operation might also help limit the interactions with the database, which might be expensive (both in terms of time and monetary cost). For instance, if our schedule repository only supported standard CRUD operations and we wanted to get all time slots for a given week, then we would have to retrieve the entire schedule from the database, and then make some filtering afterward to only get the time slots for that week. On the other hand, if our schedule repository had a dedicated method for getting all time slots in a week, then our repository could make a more optimised query to the database, that only retrieves the data that we need.
Next up
That concludes the part on central concepts of DDD. In the third and final article, I will outline a dynamic model for our system and explore the concept of refactoring in the context of Domain-Driven Design.